
廖晓格——平安银行大数据基础平台&AI部落负责人,负责平安银行大数据平台及AI平台的建设,推动银行零售智能化转型,曾就职于华为、携程、eBay、PPTV和泰为,有多年大数据平台及AI平台的研发经验。
▼
— 背景 —
— 1 —
尽管数据仓库带来许多好处,但数据仓库对金融业务发展产生的大量非结构化、半结构化数据的处理能力较弱。建设也困难重重,原先通过hadoop生态技术来降低数据存储的成本,但是由于数据量爆炸式增长,如果还是按照原先的方式构建数据,很多公司已经负担不起成本的压力,传统数据仓库的痛点逐渐显露:
数据冗余度高:据以物理表为基础的数据加工处理无可避免的带来数据的重复存储,存储的冗余度很高。例如,大多数数据集市的数据源自数据仓库,这意味着数据集市中的数据全部都是多余的;即使数据暂存区和数据仓库也包含大量的重叠数据。此外,许多重复数据以索引、物化查询表、具有聚合数据的列和表等形式存储在每个数据库内部。其直接结果就是导致数据膨胀,增长远超过业务增长。
运维成本高:传统数仓多是封闭的生态,软硬件紧耦合,多数变更、处理都依赖人力,导致运维成本较高;建模层级递进,关联耦合分析问题较多,整个链路难以监控,不仅影响范围难以评估,修复周期较长,而且数据质量监控成本、告警处置成本高;同时,传统数据仓库架构老化难以灵活扩展,在扩容时需要进行大量的数据搬迁,会影响业务的正常开展。
数据需求响应慢:新数据需求爆炸增长且变化迅速,比如领导需要的是预先构建好的报告和仪表盘,分析师想要交易明细数据,业务想要用户行为数据……不同需求都需要完成从数据的抽取、转换和加载,然后才能用于分析和挖掘,无法复用且占用大量资源,严重影响了数据的响应效率;
数据治理难:数据海啸导致数据仓库里的数据量在成倍增长,这些数据来源广泛不一,各个维度、口径难以统一,颗粒度细化难以收集,导致数据治理偏业务驱动,平台侧难以主动治理。因此治理成本高昂,效率低下。
— 2 —
新一代数仓技术方案—逻辑数仓
近年来,以Hadoop为代表的大数据平台兴起,加上云原生加持,通过虚拟技术理论上可以无限扩展足够多的服务器集群,同样算力也可以无限增强,并且能够弹性伸缩。在这种理论下,我们只用存储ODS层的数据,DWD、DWS、ADS层都是虚拟表,所有的查询、推数都可以通过强大的算力解决整个数据链路的加工,就可以解决传统数仓的痛点。但是目前算力无限大还停留在理论阶段,因此,逻辑数仓的概念也逐渐走入大家的视野,给企业解决传统数仓痛点带来新的方向。
为了达到用最小的成本来快速满足所有用户需求的目标,逻辑数仓使用用户需求驱动的手段,将所有的查询进行分析抽象后,把共性的信息进行物化处理,使得数据仓库的ROI最大化,最有效的建设数字化底座。
— 3 —
逻辑数仓定义
逻辑数仓(LDW)是架构在用户数据源基础上的一个虚拟数仓,其特点是用户需求驱动、物理分散、逻辑统一。其本质是数据消费者和数据源相互解耦,但是共享元数据规范。构建时在数据仓库和数据应用之间引进一层逻辑层,将逻辑表与物理表隔离。用户的数据检索、报表需求等通过逻辑表满足,并以用户需求驱动生成物化表,大大减少重复数据及存储成本。同时逻辑数仓弱化了繁琐的数据流加工链路,让ETL工程师更专注企业通用模型设计,也大大降低了管理成本。
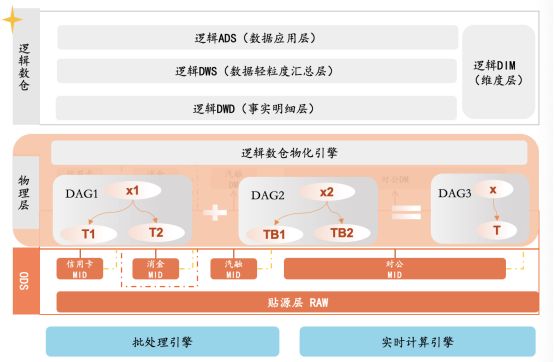
— 4 —
逻辑数仓的核心能力
物理存储层与逻辑数仓的存算解耦:新一代数据工程架构构建面向用户和下游应用消费的逻辑层,从而将逻辑表与物理表相隔离,物理表的优化由系统负责。
物理层智能调度:新一代数据工程架构实现对数据物理层的智能调度,智能调度对数据ETL逻辑和物理存储介质透明。传统的调度以静态的策略为主,而智能调度则是按需的,根据逻辑层用户行为和需求出发,实现数据生产链路的智能编排和调度,可以针对重复、相似计算进行自动合并,也可以根据统计结果对作业价值进行动态评估,下线或降权无效低频或低价值的数据的生产,大大降低了存储成本。
性能自优化:新一代数据工程架构还将做到性能的自优化。当前数据工程架构很大程度上依赖于ETL工程师对查询进行优化,对不同数据集定制和执行正确的查询性能加速方案,比如利用Cube技术优化查询性能,这占据了ETL工程师大量的时间,导致ETL工程师在数据管道上的维护时间占比过高,加重了数据需求的积压。新一代数据工程架构将基于用户查询行为实现自适应的查询性能优化,比如对于频率较高的查询自动实现物化表格、缓存或者自动构建Cube索引。
需求驱动的数据治理:与当前的计划式的数据治理模式不同,新一代数据工程的数据治理是自上而下从需求端拉动。逻辑层基于业务需求快速调整,这种调整传导至物理层,物理层进而自适应来自上层的调整,识别数据核心资产元数据。
— 5 —
未来数据仓库建设方向展望
随着数字经济时代的到来,企业数据得到极大的丰富,无论是业务用户、分析师还是数据科学家都渴望能够自助地获取到全域、高质量的数据资产,快速进行数据分析,数据可视化展示……打造低代码平台,实现数据的敏捷性和自治性,让每个人都能快速发现和理解数据,并实现主动持续的数据治理将成为数据仓库未来建设的主要方向,助力企业从数据拥有者向数据使用者转变,从点到面逐步提升金融企业数据能力。
PS,以上仅代表个人观点,欢迎各位专家参与一起讨论共创,让数据发挥更大生产力。
数据仓库
数据仓库英文名称为Data Warehouse,可简写为DW或DWH,原本是一个诞生于数据库时代的概念,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是统一数据存储,出于分析性报告和决策支持目的而创建。大数据时代的数仓延续这一概念,并发展了一整套包括了ETL、调度、建模在内的完整的数据工程体系。
ETL
大数据数仓数据工程体系整体可分为两个阶段,分别是数据采集加工处理的数据生产过程和数据分析挖掘应用的数据消费过程,我们把数据生产过程称之为ETL(Extract, Transform, Load)流程,把这个过程中涉及到的数据技术称之为ETL技术,把主导这个过程的人员称之为ETL工程师。
END
金融行业数据非常复杂,业务场景繁多,都是重度依赖大数据,包括金融营销、风控、运营、经营等场景;在零售转型过程中,如何利用数据资产支持业务快速转型,通过数字化寻找业务增长第二曲线,因此需要构建高效、稳定、安全的大数据平台及数据中台服务,快速支持数据治理、数据分析、数据探索和挖掘,让数据无处不在,发挥业务价值。作为K+全球软件研发行业创新峰会上海站的特邀演讲嘉宾,廖晓格将带来《金融数据中台演进之路》主题演讲,感兴趣的同学欢迎关注!

北京营销中心
北京通州北京ONE国际广场10层
上海研究中心
上海市浦东软件园
厦门研究中心
厦门观音山国际商务运营中心
海外市场中心
香港中环香港站国际金融中心

